2026 will be a major leap forward for our CrimeRisk data series, as we are well underway on some major revisions to the source data, models, crime types covered, and even some measures which go beyond indexed results. In the meantime – in preparation for the major overhaul – we have done some updating and fine tuning of the existing model.
The enhancements are largely of the ‘under the hood’ type. Those changes include:
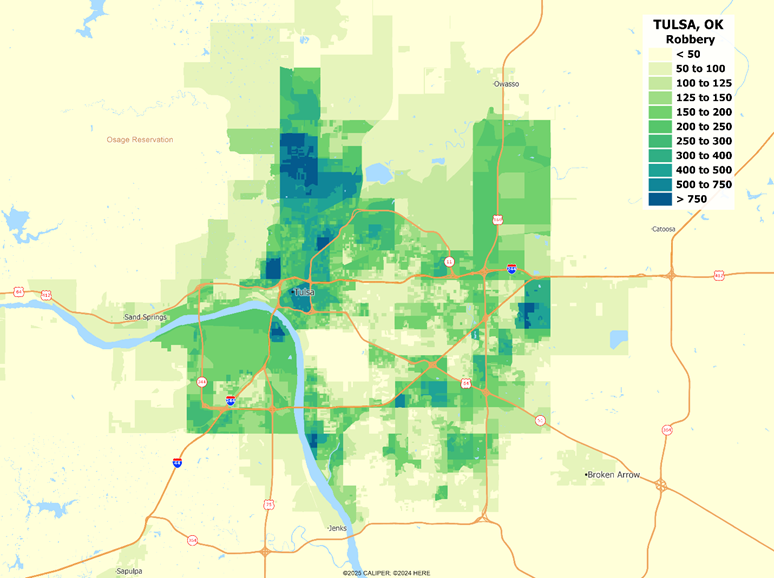
- Improved handling of the NIBRS (National Incident Based Reporting System) data which the FBI introduced a few years ago but is only slowly being adopted by local agencies. The primary change is that previous tallies in the UCR (Uniform Crime Report) included only the most egregious crime, whereas the NIBRS encourages multiple entries. The NIBRS includes a broader range of crimes with much more detail for each crime. The 2026A indexes use the latest data from the UCR and NIBRS, as well as incident data from many of the nation’s largest jurisdictions.
- An expanded set of jurisdictions for which incident level data is available and usable, which improves precision at the census block level. While CrimeRisk is not an incident reporter, we use local statistics extensively
- Revisions to the base models which improve model reliability and performance largely by expanding and revising the variables used in the models. The resulting models are less affected by autocorrelation, making the estimates more robust.
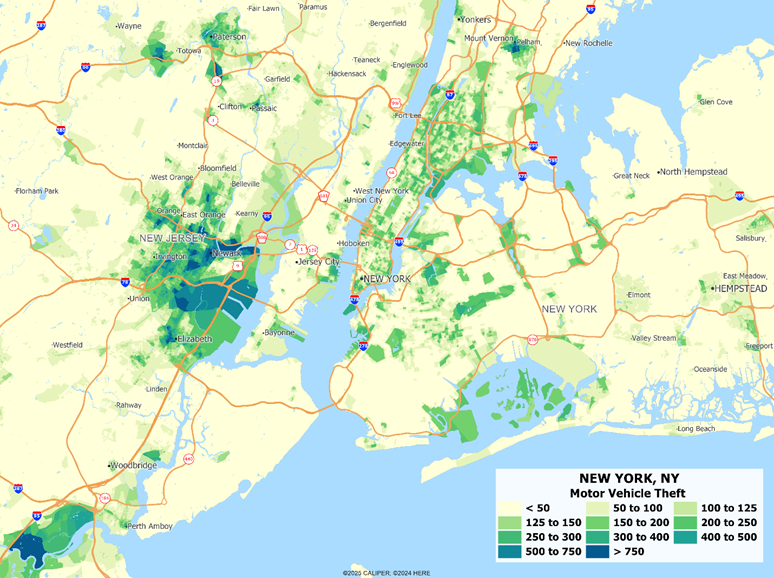
What is this major overhaul?
It will consist of several visible components –
- A broader range of crimes covered
- Seasonality and time of the week breakdowns for any crime types which exhibit significant temporal variation.
- In addition to the standard indexes, we will add crime probability estimates to answer the question ‘how many crimes of type x do we expect will occur in this area over the course of this year?’. Given that a crime like murder is a statistically rare event, we can expect to see trade area reports where the expected number of murders is non-zero, but less than one.
- Data will be produced for both the United States and Canada.
The coming release will be based on a much expanded incident dataset which covers nearly three-quarters of the population nationwide, as well as some large Canadian cities. The data will continue to be modeled using both the characteristics of residents and the types of businesses and features of the immediate vicinity. The models rely on a balance between inventory (what is in the census block) and spatial proximity (what is near the census block). More to come on this soon!