Have you ever wondered how we make estimations better than a summary table should allow? The AGS synthetic model creates individuals and households that, within any census block, match the block tables across a wide range of dimensions. This allows us, for example, to estimate complex interactions that can’t be easily represented in summary tables. At present, the model is for households only, but work is well underway to expand it to the individuals living within those households.
Assume that we have a census block that has the following three tables:
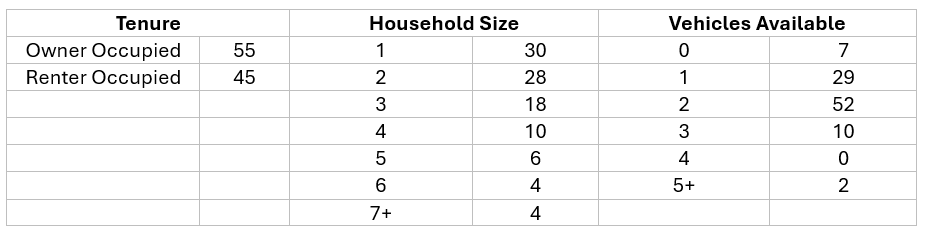
The goal is to create a set of 100 households with each of the characteristics such that the totals for each group match the individual tables. This requires establishing and modeling the nature of the relationship between each of the core variables.
These relationships have been modeled using the ACS public use micro sample in order to provide the assignment rules for individual households in a way which does not bias the results towards any one of the individual variables and results in the household characteristics exactly matching the target block totals.
Census blocks are used as the base geography for two reasons:
- The block level is the base geography for the AGS estimates and projections effort
- They are relatively small and help to contain errors introduced by the attribute assignment procedures, which in larger errors have a tendency to create more unusual outliers (such as young households in extremely expensive homes).
The assignment of characteristics to households is undertaken using methods which ensure that block totals are obtained and that there are no biases present given the order of the attribute assignment.
The initial uses of the model are:
- To enable the use of respondent level survey data to build databases such as Consumer Expenditures, which in the past have relied upon using a series of averages for each table used in the analysis that results in a loss of variance. Modeling instead at the household level, then aggregating to spatial units, preserves most of the demographically driven variance in the original sample.
- To provide a means for quickly creating cross tabulations between common tables (such as age by income) in order to match defined segments. For example, a CPG brand could identify a target group as being people aged 33-41, with at least one vehicle in the household and a household income no less than $85,000. The use of synthetic households enables us to provide estimates quickly and efficiently for any tabulation break points. Those improved estimates, done at a block level, can then be used within the Snapshot engine to deliver data for any geographic area required.
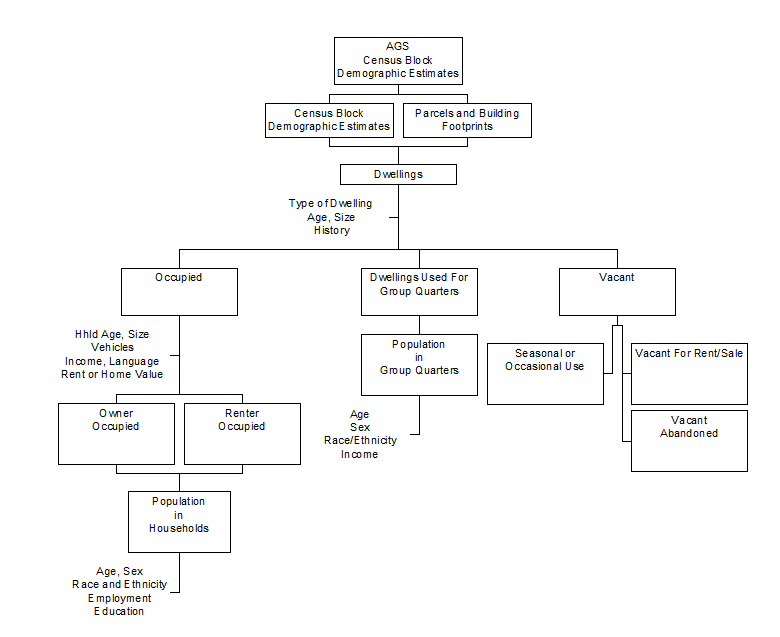
At completion, the model will consist of three sets of components which rely heavily on the AGS master address file which includes parcel boundaries and attributes:
- Dwellings
- Households
- Persons
Most of the commonly used demographic attributes with linkages between the separate groups of dwellings, households, and persons will within the synthetic model, including:
- Dwellings
- Type of dwelling (single family, multifamily, apartment)
- Year of construction
- Dwelling size
- Households
- Tenure
- Age of Householder
- Size of household
- Number of vehicles available
- Household income
- Contract rent (renters only)
- Value of housing
- Household structure (e.g. single parent male with children)
- Household language and linguistic isolation
- Persons
- Age
- Sex
- Race and ethnicity
- Educational attainment and school enrollment
- Marital status
Persons will be tied to either households or to group quarters dwellings.